Set2Model networks - Learning discriminatively to learn generative models
Alexander Vakhitov, Andrey Kuzmin, Victor Lempitsky
We present a new ”learning-to-learn”-type approach that enables rapid learning of concepts from small-to-medium sized training sets and is primarily designed for web-initialized image retrieval. At the core of our approach is a deep architecture (a Set2Model network) that maps sets of examples to simple generative probabilistic models such as Gaussians or mixtures of Gaussians in the space of high-dimensional descriptors. The parameters of the embedding into the descriptor space are trained in the end-to-end fashion in the meta-learning stage using a set of training learning problems. The main technical novelty of our approach is the derivation of the backprop process through the mixture model fitting, which makes the likelihood of the resulting models differentiable with respect to the positions of the input descriptors. While the meta-learning process for a Set2Model network is discriminative, a trained Set2Model network performs generative learning of generative models in the descriptor space, which facilitates learning in the cases when no negative examples are available, and whenever the concept being learned is polysemous or represented by noisy training sets. Among other experiments, we demonstrate that these properties allow Set2Model networks to pick visual concepts from the raw outputs of Internet image search engines better than a set of strong baselines.
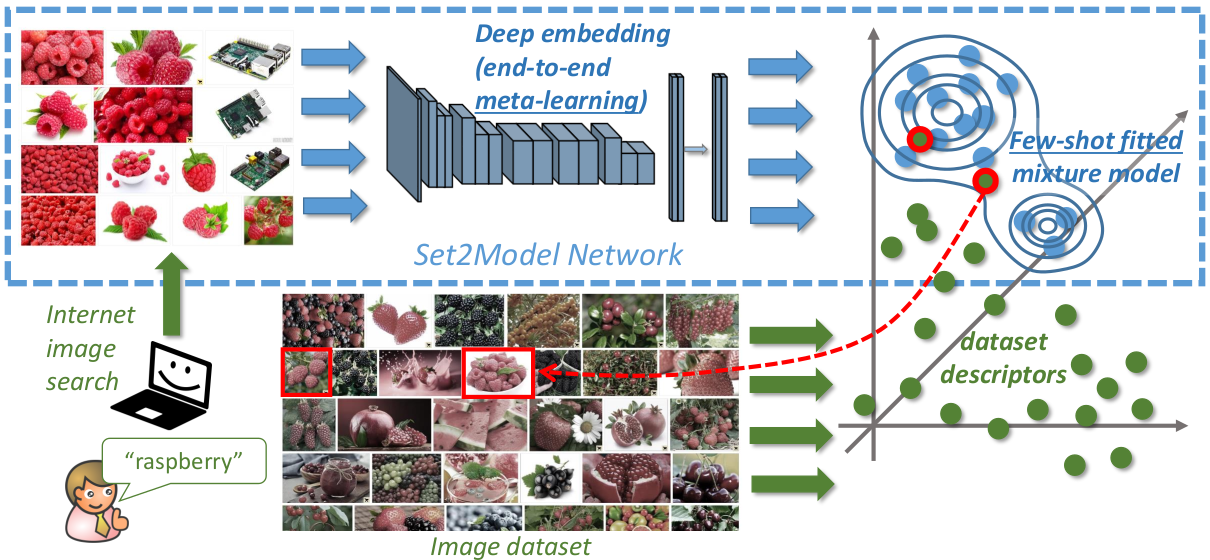
Top (blue): the Set2Model (S2M) network, which takes the set of data points (e.g. images), maps them through a non-linear architecture (e.g. a deep ConvNet) to a high-dimensional descriptor space, and then fits a generative model (e.g. Gaussian mixture) to the resulting set of descriptors. The parameters of the deep embedding are optimized in the end-to-end meta-learning stage, while the generative model is fitted in the few-shot learning stage. Bottom (green): our motivating application (Internet-based learning and retrieval). Given a visual concept “raspberry”, the user obtains a noisy image set depicting raspberries from an Internet image search engine. A pre-meta-learned Set2Model network then maps the set to a mixture model in the descriptor space. Given an unannotated dataset of images, the user can search for images with raspberries by mapping every image to the descriptor space (using the same deep embedding from the S2M network) and evaluating the likelihood w.r.t. the obtained model.
LINKS
Code
Paper
Alexander Vakhitov and Andrey Kuzmin and Victor S. Lempitsky Set2Model networks: Learning discriminatively to learn generative models, Computer Vision and Image Understanding, 2018, pp. 13–23 pdf bib